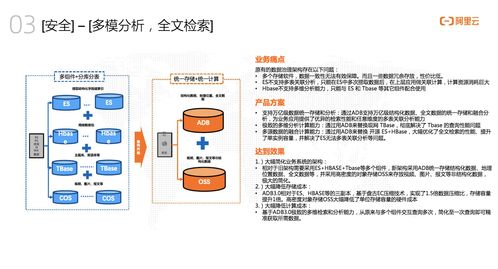
Linux服务器性能参数指标详解——数据处理服务场景
在数据处理服务中,Linux服务器的性能直接关系到数据处理的效率、稳定性和服务质量。为了确保数据处理服务的高效运行,系统管理员和开发人员需要密切关注一系列关键性能指标。本文将从CPU、内存、磁盘I/O、网络和系统负载五个维度,Linux服务器在数据处理服务中的核心性能参数指标及其监控方法。
一、CPU性能指标
CPU是数据处理的核心,其性能直接影响数据处理的速度。
- CPU使用率(CPU Utilization)
- 用户态使用率(%user):运行用户进程的时间百分比。对于数据处理服务,如果该值持续过高,可能表明应用层代码或计算逻辑存在优化空间。
- 系统态使用率(%sys):运行内核进程的时间百分比。频繁的系统调用(如I/O操作)会导致此值升高。
- 等待I/O的CPU时间(%iowait):CPU等待磁盘I/O完成的时间百分比。这是数据处理服务的一个关键指标,过高的iowait通常意味着磁盘成为瓶颈。
- 空闲率(%idle):CPU空闲时间百分比。长期过低(如<10%)可能预示CPU资源紧张。
- 工具:使用
top,htop,vmstat 1,mpstat -P ALL 1命令监控。重点关注整体使用率是否超过70-80%(警戒线),以及iowait是否异常。
- CPU负载(Load Average)
- 表示系统中处于可运行状态和不可中断状态的平均进程数。三个值分别对应1分钟、5分钟、15分钟的平均负载。
- 解读:理想情况下,负载应低于CPU核心数。对于数据处理服务器,若15分钟负载持续高于核心数的2-3倍,则系统可能已过载。
- 工具:
uptime,top命令的首行显示。
二、内存性能指标
数据处理常涉及大量数据在内存中的操作,内存管理至关重要。
- 内存使用率(Memory Usage)
- 已用内存(Used)与可用内存(Free/Available):Linux会利用空闲内存做缓存(Cached)和缓冲(Buffers),因此更应关注
Available内存,它表示真正可供程序使用的内存量。
- 交换分区使用(Swap Usage):如果数据处理服务频繁使用Swap,会导致性能急剧下降(磁盘速度远慢于内存)。应监控Swap的
si(换入)和so(换出)频率。
- 工具:
free -h,top。监控Available内存是否过低,以及Swap是否被频繁使用。
- 虚拟内存统计(vmstat)
- si/so:如上述,交换活动,理想应为0。
- bo/bi:块设备写入/读出,反映磁盘I/O活动。
三、磁盘I/O性能指标
数据处理服务(尤其是ETL、数据库、日志分析)是I/O密集型操作,磁盘性能是常见瓶颈。
- I/O利用率(%util)
- 通过
iostat -x 1查看。表示设备忙于处理I/O请求的时间百分比。持续接近100%表明磁盘已饱和。
- I/O吞吐量(rMB/s, wMB/s)
- 每秒读/写的数据量。需结合业务预期进行评估。
- I/O响应时间(await, svctm)
- await:I/O请求的平均等待时间(包括队列时间和服务时间)。通常应低于10ms,过高表示磁盘慢或过载。
- svctm:磁盘设备处理I/O请求的平均服务时间(已废弃,但可参考)。
- I/O队列长度(avgqu-sz)
- 平均队列长度。持续大于1可能表示磁盘存在瓶颈。
四、网络性能指标
对于分布式数据处理或需要读写网络存储的服务,网络性能不容忽视。
- 带宽使用率(Bandwidth Utilization)
- 监控网卡流入(RX)和流出(TX)的流量(KB/s或MB/s),是否接近网卡带宽上限。
- 工具:
sar -n DEV 1,iftop,nethogs。
- 网络连接数(TCP Connections)
- 特别是对于高并发的数据处理API服务,需要监控TCP连接状态(如ESTABLISHED, TIME_WAIT数量)。
- 工具:
ss -s,netstat -an | grep -c ESTABLISHED。
- 数据包错误与丢包(Packet Error/Drop)
- 通过
ip -s link或sar -n EDEV 1查看errs,drop计数器。非零且增长表明网络存在问题。
五、系统负载与进程级指标
- 进程监控
- 使用
top或ps aux查看关键数据处理进程的CPU、内存占用(%CPU, %MEM, RES)。
- 使用
pidstat查看指定进程的详细资源消耗(CPU、内存、磁盘I/O)。
- 文件描述符(File Descriptors)
- 数据处理服务可能打开大量文件或网络连接。监控系统级和进程级的文件描述符使用量是否接近上限。
- 工具:
cat /proc/sys/fs/file-nr,ls -l /proc/<PID>/fd | wc -l。
六、监控策略与建议
- 建立基线:在业务低峰期和高峰期分别测量性能指标,建立正常范围的基线。
- 设置告警:对核心指标(如CPU负载>核心数*2、可用内存<10%、磁盘使用率>90%、iowait>30%、网络丢包>0)设置阈值告警。
- 关联分析:性能问题往往关联出现。例如,高iowait可能伴随内存不足(触发Swap)和CPU负载升高。
- 使用专业工具:结合
Prometheus+Grafana+node_exporter等现代监控栈进行持续采集、可视化和告警,替代单次命令查询。
对于Linux服务器上的数据处理服务,性能优化是一个持续的过程。通过系统地监控和分析上述CPU、内存、磁盘I/O、网络及系统负载指标,可以快速定位瓶颈,预测资源需求,从而保障数据处理任务的稳定高效运行,为业务提供可靠的数据服务支撑。
如若转载,请注明出处:http://www.qnzby2973.com/product/59.html
更新时间:2026-04-04 05:29:02